
Applying Translation Mistakes Classifications To Work Out The Translation Quality Assessment Criteria


Abstract
This work considers the existing classifications of translation mistakes and provides the generalized scheme for the most applicable ones. The given classification enables to create the translation quality assessment criteria. The main goal of this work is to find out the most frequent types of translation mistakes. For this purpose, we have made statistics on the students’ translations of the same text to find the most common mistakes or so-called ‘traps’. The analysis of semantic mistakes showed that, as a rule, they are associated with a misunderstanding of the general content of the text segment or a wrong choice of an inappropriate meaning of a polysemic word. Mistakes of the content provoke language mistakes since they are the cause of ambiguities and inaccuracies. The assessment of the non-linguistic students’ translations in accordance with the described criteria justifies the significance of academic writing skills in the first language. Proofreading should become an integral part of the translator’s training.
Keywords: Assessment criteria, loose translation, literal translation, translation mistake
Introduction
To date mastering English as the global language of international communication is becoming a key competence of a competitive specialist. First of all, this concerns access to the professional literature in English. The technical specialist should be able to get up-to-date information without a translator. Taking this into account future graduates of a technical university should have sufficient language training, which involves translation and comprehension skills.
The mechanisms of the translation process are not well understood, because we cannot directly observe the mental activity. The literature on translation studies expresses an opinion that two complementary mental activities take part in the translation process. One way is to use standard substitutions and transformations when the translator implements the ‘symbol – symbol’ technique. The more complex activity ‘symbol - reflection – symbol’ requires a more thoughtful state from the translator: they delve into the content of the source text (ST) and create a ‘reflection’ of the content of ST based on their general and professional knowledge. Therefore, with this ‘reflection’, the translator conveys the author’s ideas and emotions through the translating language. This mental activity finds its expression in complex translation transformations (Catford, 1965).
The automatic translation technique using standard translation equivalents allows a translator to concentrate on difficult places, which saves mental effort. Thus, the translation technique involves the competence of using ready-made translation equivalents without thinking to be able to concentrate on complex parts of the text, to find non-standard equivalents.
Prevalence of one technique over the other results in the emergence of fundamentally two types of translation mistakes – loose and vice versa literal translation. A loose translation is understood as a translation mistake, which involves the transfer of formal or semantic components of a word, phrase, or a collocation to the detriment of its meaning or structural information (Minyar-Beloruchev, 1999). Sometimes a translator may put stress on communicatively irrelevant elements of the source text, which leads to a violation of language norms and usage of the target language, or the actual content of the source text is distorted. By loose translation, we understand the transfer of key information without taking into account the formal and semantic components of the source text (Komissarov, 1990).
Problem Statement
According to some authors (Komissarov, 1990; Latyshev & Semenov, 2003), literal translations are most frequent content mistakes, so when teaching translation, the teacher should introduce students to the most common translation equivalents, focus on their usage, and focus on the use of cliches. It is necessary to develop the skills of transformation within the same language, to express the content in different language forms on different lexical material and grammar structures. Mastering these transformation skills helps the translator to find the most optimal translation option.
Since the translator aims to convey the content of the text through another language, the pragmatic aspect is a priority. Garbovsky (2007) discusses the ‘maximum level of admissibility’ of transformations.
It is important to see what elements carry a functional load and must be translated, and what elements can be modified, replaced, or omitted. We should note that in technical translation the omission technique should be used extremely carefully (Kruger, 2016).
In the phase of the primary perception, a translator is believed to divide the text into simple and complex elements. First, simple segments are translated, and then the translated elements form the basis to start translating more complex elements (Latyshev, 2000). In particular, lexical compatibility may dictate the choice of a particular word or structure. Currently, modern corpus computational linguistics offers a new approach to the study of the phenomenon of lexical compatibility. Words are defined by the structures they are combined in the text and vice versa. The translator can refer to an authoritative body of the target language texts to check their choices.
At the next stage, the translator's assumptions about the reactions of native speakers of the source language (SL) and native speakers of the target language (TL) to the source text and the translated text are compared. As mentioned earlier, the translator perceives the source text through the prism of their own experience, and therefore primarily focuses on their reaction to the translated text as a native speaker of the TL. At this point, one should abstract from the created text to some extent, to put it into perspective. According to the suggestion of Schweitzer, the translator should compare some characteristic generalized-averaged reactions. The translator may prefer individual syntactic or grammar structures, may have favorite words and expressions. The individual preferences in translation should not attract the reader's attention, distort the overall content of the text and they should conform to the genre of the source text. As is the case, one of the students when translating English texts into Russian overused the word отнюдь, although this word has about 17 synonyms, and is not a frequent one. Thus, the frequency of using its word-synonym is 86,615 times per ≈ 300 million words, and the word is only 5,476 times per ≈ 300 million words. Therefore, the translator's personality was reflected in the translation, which led to a stylistic discrepancy.
At the control stage, the translator works with the primary version of the translation, identifies those elements that make it difficult to comprehend the message, and produces a negative communicative impact. Further, by selecting other options and changing the structure of the PT, the translator corrects the problematic elements. Sometimes the search for the optimal translation of a complex element can lead to a modification of some previously translated by standard means text segment and cause a conflict between these two emerging translated statements, and the translator has to redo the previously translated text sections. Most often the sources of difficulties are idioms, lexical-semantic and grammatical compatibility, illogical norms, etc. The ability to detect, classify and eliminate mistakes in translation is of great importance. Proofreading is an integral part of translation training (McGrath, 2014).
The objective of this study is to consider the existing classifications of translation mistakes to make the basis of the translation assessment criteria.
Research Questions
This research aims to find the most frequent types of translation mistakes. Knowing the most typical difficulties will help to make recommendations for the most efficient training in translation.
Purpose of the Study
The purpose of this work is to analyze the translations of non-linguistic students and identify the most frequent translation mistakes. This analysis will show the most common types of mistakes, and therefore what we should pay attention to when teaching translation. This study aims to provide the generalised scheme for the translation quality assessment criteria. Applying these classifications will help to determine the typical translation mistakes of non-linguistic translator students.
Research Methods
The translation quality can be judged by the presence or absence of mistakes in it. Often, the translation evaluation is based on understanding what is bad in the translation. The evaluation of a training translation in practice involves subtracting a certain number of points from the "perfect" version, for successful translation solutions, points can be added. The weighting factor of points may vary depending on the type of translation mistake.
Contemporary translation studies provide several classifications of translation mistakes. In (Komissarov, 1990) the author offers a semantic classification, where mistakes are ranked according to the degree of distortion of the original content in translation. Such a system enables the evaluation of the quality of translation by a numerical rating scale. The author identifies four basic types of mistakes with different ranking, which can be taken into account when evaluating the translation quality:
1. Gross distortion of the original content occurs due to the translator's misinterpretation of the ST content and leads to actual misinformation of the Receptor. The reasons for the mistake are obvious, such as an incorrect reading of the original text, ignorance of grammatical and lexical phenomena, lack of technical or country-specific knowledge, etc.
2. Inaccurate convey of the original message when the meaning is conveyed inaccurately or incompletely.
3. Ambiguity occurs when the meaning of ST cannot be completely clear in еру translation, it is often caused by a poor choice of a word or a syntactic structure, as well as by some inappropriate structure replacement.
4. Violations of the common language norms and rules of the target language do not affect the translation equivalence but indicate that the translator was not able to cope with the influence of the source language.
In (Latyshev, 2000; Latyshev & Semenov, 2003) the author divides mistakes into semantic (mistakes of the content plan), and linguistic. This classification allows the application of a more formalized approach to the assessment of the translation quality. Figures 1 and 2 below show a generalized classification of language and semantic mistakes respectively. These classifications make the basis of this work.
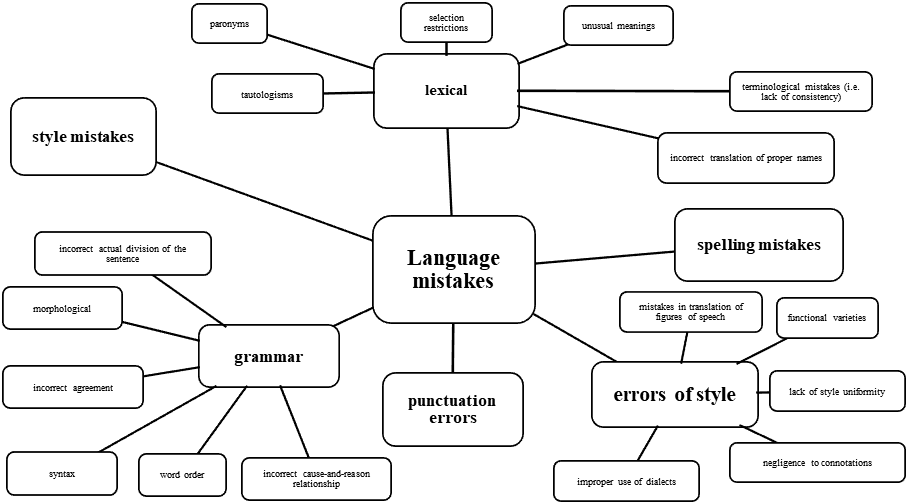
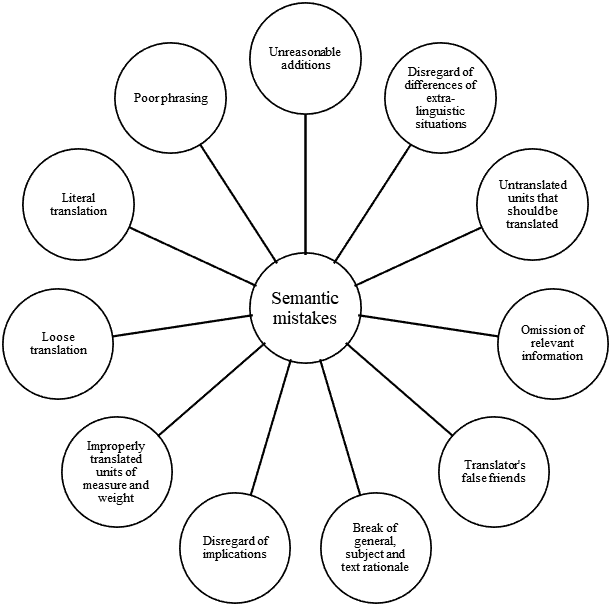
In his work (Latyshev & Semenov, 2003) the author gives a vivid example of the lexis that provokes translation mistakes. He describes the case of court proceedings connected with the accusation of a translator with plagiarism. The reason for the appeal to the court was the repetition of the mistakes of the first translator by the author of a later translation. To conduct an expert examination for this case, the court turned to the authoritative translator Retsker, who made an interesting linguistic experiment with the participation of senior students of the Translation Faculty of the Moscow State Technical University. The participants of the experiment translated the same text, making many identical mistakes in the translation. The experiment showed that translation mistakes can often occur not only through the lack of translator’s competence but also due to certain ‘provoking’ ST factors. The translator must be aware of the possible existence of such ‘traps’ in IT and be prepared to see them. The charge of plagiarism was withdrawn due to the experiment of Retsker.
From a practical point of view, such an experiment is interesting because it enables not only to find the ‘traps’ of ST, but also to determine the most frequent types of mistakes that inexperienced translators make, and in the future to devote more time and effort to work on their elimination.
Findings
The study analyzed 23 papers of junior students of non-linguistic specialties of NSTU. The works took into account the mistakes made by the majority of students, the above-mentioned ‘traps’. It should be noted that some individual mistakes caused by student’s unwariness, incorrect interpretation of the text, and omissions of text parts were not considered, since such mistakes do not belong to the ‘traps’ of ST, but were taken into account statistically (Medvedeva, 2020).
The research material was a scientific and journalistic text on the topic "Environmental problems". Within 60 minutes, students were supposed to make a written translation of the text (Molles, 2016).
As a reference for checking we used the translation made collectively by several teachers of the Department of Foreign Languages for Technical Faculties at NSTU. The analysis of semantic mistakes showed that, as a rule, they are associated with a misunderstanding of the general content of the text segment or a wrong choice of an inappropriate meaning of a polysemic word. Mistakes of the content plan, however, are inextricably linked with language mistakes, since they are the cause of ambiguities and inaccuracies. For example, an inappropriate translation of the word combination as can be considered as a lexical mistake (omission of relevant information), which leads to inaccuracy (it has a lower degree of misinforming effect than distortion; it does not distort the content of the original text, but requires clarification).
Statistical data on the number of different types of mistakes made show that most of them are caused by lexical compatibility and incorrect subject-verb and noun-adjective agreement. Most of these mistakes occur because students do not see the subordinate relationship between the main and the dependent word when between them there are other elements. There is also a very high proportion of literal translations, especially the excessive use of terms. Loose translations are not very common, but if they appear, they have a very individual character, and it is impossible to attribute them to ‘traps’ or give a logical explanation to their appearance. For example, we cannot explain the translation as (countries with a low crime rate). (Vottonen, 2021) provides the comprehensive argument to illustrate these phenomena. Thus, when teaching translation, it is desirable to pay attention to the formation of the ability to see syntactic connections, focus on the general content of IT, and check translation options.
It is also necessary to pay attention to a certain key point. A large number of normative-language mistakes and standard deviations in the translated text make the reader doubt the competence of the translator, distrust him/her as a language intermediary. This is evidenced by special studies (Screen, 2019). The students’ translations practically have no distortions, and the general content of ST is perfectly understood and conveyed, but a huge number of small language mistakes make a low total score.
To form an idea of what a bad and good translation is, translator students should analyze other students’ mistakes, which gives a greater degree of criticality and objectivity (Hu et al., 2019).
Conclusion
To sum up, we should emphasize that the ability to see the translated text from a perspective becomes very valuable; the knowledge of standard translation solutions and techniques helps to free up time for working with complex elements. According to the author, most of the mistakes made in the translation could be avoided if students had the skills of self-editing and the ability to allocate time.
References
Catford, J. C. (1965). A linguistic theory of translation. Oxford University Press.
Garbovsky, N. A. (2007). Theory of translation. Moscow State University Press.
Hu, X., Xiao, R., & Hardie, A. (2019). How do English translations differ from non-translated English writings? A multi-feature statistical model for linguistic variation analysis. Corpus Linguistics and Ling. Theory; 15(2), 347–382. DOI:
Komissarov, V. N. (1990). Theory of translation (linguistic aspects). Vysshaya shkola.
Kruger, R. (2016). The textual degree of technicality as a potential factor influencing the occurrence of explicitation in scientific and technical translation. The Journal of Specialised Translation, 26. https://www.jostrans.org/issue26/art_kruger.pdf
Latyshev, L. K. (2000). Translation technique. NTVI-Thesaurus.
Latyshev, L. L., & Semenov, A. L. (2003). Translation: theory, practice and teaching techniques. Academia.
Molles Manuel C. (2016). Ecology: concepts and applications. McGrow-Hill Education.
McGrath, L. (2014). Parallel language use in academic and outreach publication: A case study of policy and practice. Journal of English for Academic Purposes, 13, 5-16 DOI:
Medvedeva, N. P. (2020). Translation Mistakes and Solutions in Translating Scientific and Journalistic Texts from English. Issues of Modern Science, joint monograph. Internauka, 57, 124-140.
Minyar-Beloruchev, R. K. (1999). How to be a translator? Gotika.
Screen, B. (2019). What effect does post-editing have on the translation product from an end-user’s perspective? The Journal of Specialised Translation, 31. https://jostrans.org/issue31/art_screen.php
Vottonen, E. (2021). On what grounds? Justifications of student translators for their translation solutions. The Interpreter and Translator Trainer, 14(4). DOI:
Copyright information

This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License.
About this article
Publication Date
02 December 2021
Article Doi
eBook ISBN
978-1-80296-117-1
Publisher
European Publisher
Volume
118
Print ISBN (optional)
-
Edition Number
1st Edition
Pages
1-954
Subjects
Linguistics, cognitive linguistics, education technology, linguistic conceptology, translation
Cite this article as:
Medvedeva, N. (2021). Applying Translation Mistakes Classifications To Work Out The Translation Quality Assessment Criteria. In O. Kolmakova, O. Boginskaya, & S. Grichin (Eds.), Language and Technology in the Interdisciplinary Paradigm, vol 118. European Proceedings of Social and Behavioural Sciences (pp. 116-122). European Publisher. https://doi.org/10.15405/epsbs.2021.12.16